![[Kafka] 심화 개념 및 이해](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F0Rtyj%2FbtsHJSLyzuX%2FV854EOaN4iRPpWjdoUKGrK%2Fimg.png)
Producer Acks, Batch, Page Cache, Flush
Producer Acks Parameter
Producer는 Kafka가 메시지를 잘 받았는지 어떻게 알까?
이를 확인하기 위해 Producer Acks라는 Producer Parameter를 쓴다. (Network의 그 ack 개념과 유사)
Kafka는 메시지를 받으면 잘 받았다는 의미의 acks를 보내고 Producer는 acks가 와야 다음 메시지를 보낸다.
- acks = 0 : ack가 필요하지 않음. 이 수준은 자주 사용되지 않음. 메시지 손실이 다소 있더라도 빠르게 메시지를 보내야 하는 경우에 사용
- acks = 1 : (default 값) Leader가 메시지를 수신하면 ack를 보냄. Leader가 Producer에게 ACK를 보낸 후, Follower가 복제하기 전에 Leader에 장애가 발생하면 메시지가 손실. "At most once 최대한번" 전송을 보장
- acks = -1 : (acks = all과 동일) 메시지가 Leader와 모든 Replica까지 Commit되면 ack를 보냄. Leader를 잃어도 데이터가 살아남을 수 있도록 보장. 그러나 대기 시간이 더 길고 특정 실패 사례에서 반복되는 데이터 발생 가능성 있음. "At least once최소 한번" 전송을 보장
-> 관련 Parameter
min.insync.replicas: acks=all로 설정되어 있을 때 write를 성공하기 위한 최소 복제본의 수. Producer의 옵션이 아니고 broker의 옵션. Broker의 config/sever.propercies 파일에서 설정을 변경할 수 있음. (default 1). min.insync.replicas의 값과 replication factor(복제본수 +1) 수에 다라 프로듀서의 메시지가 성공 또는 실패로 결정 되므로 정확히 이해하고 사용하는것이 중요.
Producer Retry를 위한 Parameter
retries: 메시지를 send하기 위해 재시도하는 횟수. 즉 에러가 나는 경우 몇 번 전송을 재시도 하겠는지 (default 0)
retry.backoff.ms: 재시도 사이에 추가되는 대기 시간. ex) 1회 시도와 2회 시도의 사이의 시간 (defualt 100)
request.timeout.ms: Producer가 응답을 기다리는 최대 시간
delivery.timeout.ms: send() 후 성공 또는 실패를 보고하는 시간의 상한시간.
-> delivery.timeout.ms >= linger.ms + request.timeout.ms 여야 함.
Producer Batch 처리 Parameter
처리량을 향상시키기 위해 batch로 전송한다.
사용되는 옵션
1. linger.ms(default: 0): 메시지가 함께 Batch 처리될 때까지 대기 시간. Batch에 적재되지 전까지 얼마나 데이터를 기다리느냐.
2. batch.size(default: 16kb): 보내기 전 Batch 최대 크기
-> 보통 linger.ms = 100, batch.size = 1000000
-> linger.ms = 0의 경우 send()를 호출하자마자 바로 전송함. 이 경우 매번 send()가 호출될 때마다 TCP 통신을 맺어 데이터를 전송하기 때문에 대규모 데이터 전송에서는 적합하지 않음. 이를 위해 일부 딜레이를 가지고 batch.size만큼 데이터가 모일 때까지 기다렸다가 한번에 전체 데이터를 보내는 방법을 사용

3. max.in.flight.requests.per.connection: Producer가 한번에 보내는 Batch 수. 이때 앞에 Batch가 실패하고 다음 배치가 성공하면 순서가 달라짐 enable.idempotence parameter 사용해서 해결.
4. enable.idempotence: 하나의 Batch가 실패하면, 같은 Partition으로 들어오는 후속 Batch들도 OutOfOrderSequenceException과 함께 실패함. 메시지 순서 보장(true), 메시지 순서 보장X(false)
Page Cache와 Flush
디스크 I/O의 비용이 크지만 Kafka는 데이터를 Broker의 로컬 디스크에 저장한다. 그럼에도 kafka가 빠른 이유 중 하나는 Page Cache를 사용하기 때문이다.
Producer에서 발행한 메시지가 저장되는 과정은 다음과 같다.
Producer -> (send) -> Broker Process -> (write) -> OS Page Cache -> (flush) -> Disk
여기서 성능을 위해 메시지가 저장되는 Log Segment는 우선 OS Page Cache에 기록이된다.
Zero-copy: 데이터가 user space에 복사되지 않고, 'CPU 개입 없이' Page cache와 Network buffer 사이에서 직접 전송되는 것을 의미. 이것을 통해 'Broker Heap 메모리를 절약'하고 엄청난 처리량을 제공 (카프카 특징)
Flush 되는 시점: Broker가 종료되는 경우 & OS background "Flusher Thread"실행
-> flush 되기 전에 Broker 장애가 발생하면? Replication 에서 데이터가 복구
flush에는 여러 옵션이 있지만 카프카는 디폴트 옵션을 권장함
Replica Failure
- Follower가 실패하는 경우, Leader에 의해 ISR 리스트에서 삭제되고, Leader는 새로운 ISR을 사용하여 Commit함
- Leader가 실패하는 경우, Controller는 Follower 중에서 새로운 Leader를 선출하고, Controller는 새 Leader와 ISR 정보를 먼저 ZooKeeper에 Push한 다음 로컬 캐싱을 위해 Broker에 Push함
- Leader가 선출될 때까지 해당 Partition을 사용할 수 없게 됨 -> Producer의 send()는 retries 파라미터가 설정되어 있으면 재시도하는데 retries = 0이면 NetworkException이 발생함
Replica Recovery
1. acks=all인 경우

여기서 M3, M4를 커밋하기 전에 Leader X가 죽게되면?

Y가 새로운 Leader가 되고 Z는 Y의 M3를 복제해감
Producer는 M3, M4에 대한 ack를 받지 못했으므로 M3, M4를 Y로 다시 보냄.
idempotence = false(순서 보장X)이므로 M3는 중복발생
-> 만약 X가 다시 복구되면? Leader Y로부터 복제를 하기 시작하는데, Leader Epoch를 확인해서 Leader가 바뀐 시점부터 복제함.

2. acks=1인 경우
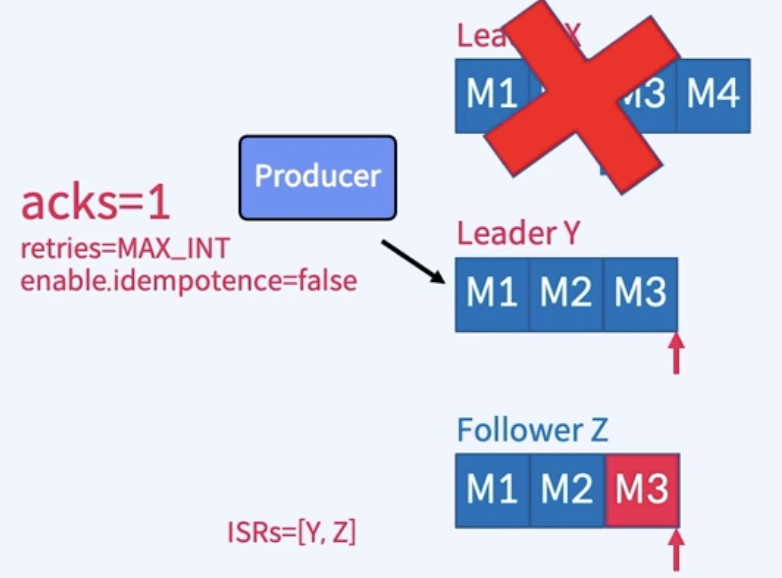
Leader X가 장애나기 전에 Producer는 M4에 대한 ack를 이미 받았을 것임(acks=1)
따라서 Y가 새로운 Leader로 선출되었을 때 M4를 영원히 잃어버리게됨
가용성(Availability)과 내구성(Durability) 관련 Parameter -> 상황에 맞게 선택 필요
- Topic Parameter - unclean.leader.election.enable
- ISR 리스트에 없는 Replica를 Leader로 선출할 것인지에 대한 옵션(default: false)
- false) ISR 리스트에 Replica가 하나도 없으면 Leader 선출을 안함 -> 서비스 중단
- true) ISR 리스트에 없는 Replica를 Leader로 선출 -> 데이터 유실
- Topic Parameter - min.insync.replicas
- 최소 요구되는 ISR의 개수에 대한 옵션(default: 1)
- ISR이 min.insync.replicas보다 적은 경우, Producer는 NotEnoughReplicas 예외를 수신
- Producer에서 acks=all과 함께 사용할 때 더 강력한 옵션 (min.insync.replicas = 2)
- replicaion factor = 3인데 3개 다 기다리는게 아닌 2개까지만 복제되면 ack를 리턴하겠다 -> 성능상으로 유리
- N개의 Replica가 있고 min.insync.replicas = 2인 경우 (N-2)개의 장애를 허용할 수 있음 -> 2개 만큼의 replica가 있어야 하니까
그렇다면 가용성과 내구성중 어떤걸 선택?
내구성을 높이려면 (데이터 유실이 없도록 하려면)
- replication.factor > 2
- acks = all
- min.insync.replicas > 1
데이터 유실이 있더라도 가용성을 높이려면
- unclean.leader.election.enable = true
Consumer Rebalance
기본 지식
Consumer 동작방식: Consumer는 메시지를 가져오기 위해 Partition에서 연속적으로 Poll 함. 그리고 가져온 위치를 나타내는 offset 정보를 __consumer_offsets Topic에 저장해서 관리
Consumer Load Balancing: 동일한 group.id로 구성된 모든 Consumer들은 하나의 Consumer Group을 형성
Partition Assignment
할당이 어떻게 될까?
- 하나의 Partition은 지정된 Consumer Group 내의 하나의 Consumer만 사용
- 동일한 key를 가진 메시지는 동일한 consumer가 사용
- Consumer의 설정 파라미터 중에서 partition.assignment.strategy로 할당 방식 조정
- Consumer Group은 Group Coordinator라는 프로세스에 의해 관리됨
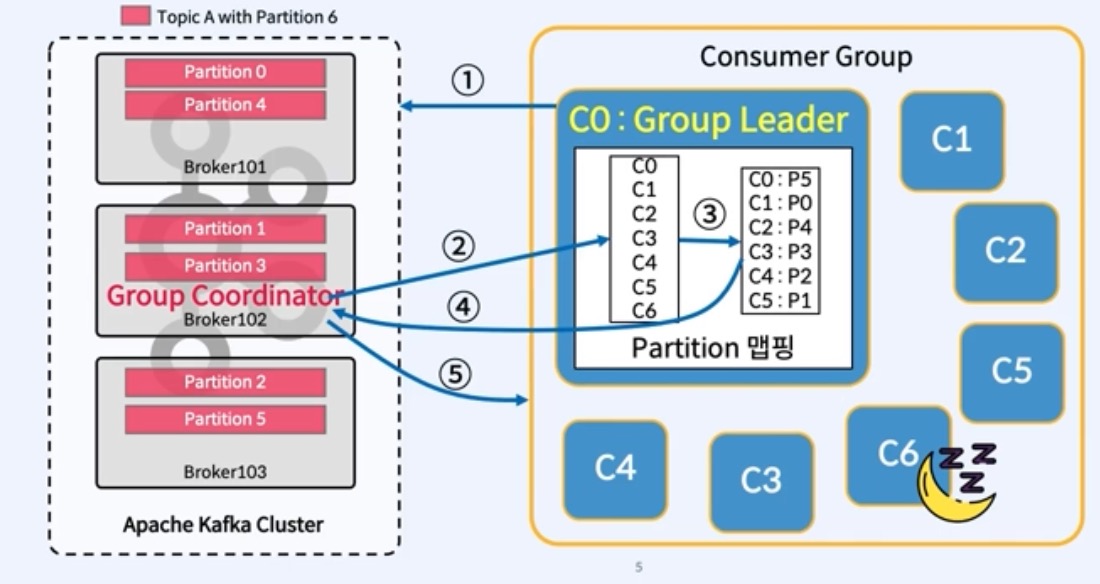
Consumer가 어떤 partition을 할당할건지 Group Coordinator와 Group Leader가 상호작용하며 관리됨
전제: Partition 0 ~ 5까지 있는 Topic A가 하나 있고, Consumer 0~6까지 있는 Consumer Group이 있다. (Partition개수보다 Consumer가 개수가 1개더 많다)
1. 각 Consumer는 group.id로 Kafka 클러스터에 자신을 등록한다. Kafka는 Consumer Group을 만들고 Consumer의 모든 Offset은 __consumer_offsets Topic의 하나의 Partition에 저장된다. 이 Partition의 Leader를 가지고 있는 Leader Broker는 Consumer Group의 Group Coordinator로 선택된다.
-> hash(group.id) % offsets.topic.num.partitions (default 50) 수식을 사용하여 offset이 저장될 __consumer_offsets의 partition을 결정
-> 결정된 partition의 leader가 어디있는지에 따라 이 consumer group의 Group Coordinator가 결정됨
2. Broker(Group Coordinor)에 붙게된 Consumer들은 Group Coordinator에 JoinGroup 요청을 날리게됨(7개의 모든 Consumer가 보냄)
-> 이를 대기하는 시간을 결정하는 파라미터: group.initial.rebalance.delay.ms(default 3초)
-> Group Coordinator는 JoinGroup 요청 순서에 따라 Consumer를 나열해서 Group Leader에게 던져준다. (Group Leader는 가장 먼저 JoinGroup 요청한 Consumer가 됨. 여기서는 Consumer 0번)
3. Group Leader는 Group Coordinator로부터 Consumer 목록을 받아서 partition.assignment.strategy 파라미터에 지정된 할당 방식으로 Consumer에 Partition을 할당함.
4. Group Leader는 할당된 정보를 Group Coordinator로 보내게 됨. Group Coordinator는 맵핑정보를 메모리에 캐시하고 ZooKeeper에 유지
5. Group Coordinator는 각 Consumer에 할당된 Partition 정보를 보냄. 각 Consumer는 할당된 Partition에서 Consume을 시작함.
-> 왜 Group Coordinator(Broker)가 할당하지 않고 Group Leader가 Partition을 할당할까? Kafka의 한가지 원칙은 가능한 한 많은 계산을 클라이언트에 수행하도록 하여, Broker의 부담을 줄임. 많은 Consumer Group이 있으면 Broker 혼자 Rebalance하기 위한 계산이 부담임
Consumer Rebalancing Trigger
이렇게 할당하는 과정은 Consumer가 새로 Consumer Group에 들어왔다던지 하면 바로 Trigger가 되어서 rebalancing이 시작됨 -> 불필요한 Rebalancing은 피해야함
Rebalancing Trigger되는 상황
- Consumer가 Consumer Group에서 탈퇴
- 신규 Consumer가 Consumer Group에 합류
- Consumer가 Topic 구독을 변경
- Consumer Grouop은 Topic 메타데이터의 변경 사항을 인지 (ex. Partition 증가)
Rebalancing Process
1. Group Coordinator는 heartbeats의 플래그를 사용하여 Consumer에게 Rebalance 신호를 보냄
2. 모든 Consumer가 일시 중지하고 Offset을 commit
3. Consumer는 Consumer Group의 새로운 generation에 다시 합류
4. partition 재할당
5. Consumer는 새 Partition에서 다시 Consume을 시작
-> Consumer Rebalancing시 Consumer들은 메시지를 Consume하지 못함. 따라서 불필요한 Rebalancing은 반드시 피해야 함
Consumer Heartbeat
: Consumer 장애를 인지하기 위함
- Consumer는 데이터를 읽어오는 poll()과 별도로 백그라운드 Thread에서 Heartbeats를 계속 보냄(Consumer가 살아있음을 의미) -> heartbeat.interval.ms(default 3초)
- 아래 시간동안 heartbeats가 수신되지 않으면 Consumer는 Consumer group에서 삭제됨 -> session.timeout.ms(default 10초)
- poll()은 heartbeats과 상관없이 주기적으로 호출되어야 함 -> max.poll.interval.ms (default 5분)
과도한 rebalancing을 피하는 방법
1. Consumer Group 멤버 고정하기
- Group의 각 Consumer에게 고유한 group.instance.id를 할당하기
- Consumer는 LeaveGroupRequest를 사용하지 않아야 함. 사용하면 rebalancing 되기 때문. 동일한 group.instance.id를 사용한다는것은 잠시 나갔다가 다시들어온다는 의미임(rebalancing X)
- 즉, Rejoin(재가입)은 알려진 group.instance.id에 대한 rebalance를 trigger하지 않음
2. session.timeout.ms 튜닝하기
- heartbeat.interval.ms를 session.timeout.ms의 1/3로 설정
- group.min.session.timeout.ms (default 6초)와 group.max.session.timeout.ms(default 5분)의 사이값
- 숫자가 크면? Consumer가 rejoin할수 있는 더 많은 시간을 제공
- 숫자가 작으면? Consumer 장애를 감지하는데 시간이 더 오래 걸림
3. max.poll.interval.ms 튜닝하기
- Consumer에게 poll()한 데이터를 처리할 수 있는 충분한 시간을 제공해야함. 단, 너무 크게 해도 안됨 -> 테스트하면서 적절한 값을 찾아가야함
Partition Assignment Strategy
Partition 할당 방식 -> partition.assignment.strategy로 할당방식 설정
1. org.apache.kafka.client.consumer.RangeAssigner (default)
-> Topic별로 작동. “순서대로”
-> 동일한 Key를 가지고 있는 메시지들에 대한 Topic들 간에 co-partitioning하기 유리
2. org.apache.kafka.clients.consumer.RoundRobinAssignor
-> Round Robin 방식으로 Consumer에게 partition을 할당
-> Topic별로 작동하지 않고 “순서대로”
-> 재할당될 때, Consumer가 동일한 Partition을 유지한다고 보장하지 않음
-> Consumer간 Subscribe해오는 Topic이 다른 경우, 할당 불균형이 발생할 가능성 있음 -> 문제해결 sticky assignor
3. org.apache.kafka.clients.consumer.StickyAssigner
-> 최대한 많은 기존 Partition 할당을 유지하면서 최대 균형을 이루는 할당을 보장
-> Round Robin 문제해결: Consumer들에게 할당된 Topic Partition 수는 최대 1만큼 다름. 특정 Consumer(A)가 다른 Consumer(B)들에 비해 2개 이상 더 적은 Topic Partition이 할당된 경우, A에 할당된 Topic의 나머지 Partition들은 B에 할당될 수 없음.
-> 재할당이 발생했을 경우, 기존 할당을 최대한 많이 보존하여 유지: topic partition이 하나의 consumer에서 다른 consumer로 이동할 때의 오버헤드를 줄임
-> 특정 Consumer가 죽었다고 할 때, Round Robin은 전체 재할당하지만 stickyAssignor는 기존 할당은 유지하면서 갈곳잃은 partition들만 재할당함
4. org.apache.kafka.clients.consumer.CooperativeStickyAssignor
-> 동일한 StickyAssignor 논리를 따르지만 협력적인 rebalance를 허용
5. org.apache.kafka.clients.consumer.ConsumerPartitionAssignor
-> 인터페이스를 구현하면 사용자 지정 할당 전략을 사용할 수 있음
Kafka Log File
Segment File을 좀 더 자세히 살펴보자.
Kafka Log Segment File Directory
- Segment File이 생성되는 위치: 각 Broker의 server.properties 파일 안에서 log.dirs 파라미터로 정의됨 (콤마로 구분하여 여러 디렉토리 지정 가능)
ex) log.dirs = /data/kafka/kafka-log-a,/data/kafka/kafka-log-b
- 각 Topic과 그 Partition은 log.dirs 아래에 하위 디렉토리로 구성
- 생성되는 Log file명에는 의미가 있음 -> 00000000...12345.log -> 시작 offset을 의미. 만약 다음 파일이 0000...34567.log라면 0000...34567 - 1 까지 offset이 작성되었다는 의미
Partition 디렉토리에 생성되는 File Types 최소 4가지
- Log Segmenet File: 메시지와 metadata 저장 -> .log
- Index File: 각 메시지의 offset을 Log segment 파일의 Byte 위치에 매핑 -> .index
- Time-based Index File: 각 메시지의 timestamp 기반으로 메시지를 검색하는데 사용 -> .timeindex
- Leader Epoch Checkpoint File: Leader Epoch과 관련 Offset 정보를 저장 -> leader-epoch-checkpoint
Reference
출처: 패스트캠퍼스 Kafka 완전 정복: 클러스터 구축부터 MSA 환경 활용까지
'TIL' 카테고리의 다른 글
| [Kafka] Kafka Consumer의 commit을 제어하는 enable.auto.commit과 AckMode (0) | 2024.08.20 |
|---|---|
| [Spring] Servlet부터 Filter와 Interceptor까지 (0) | 2024.07.24 |
| [Kafka] 기본 개념 및 이해 (0) | 2024.04.16 |
| [쿠버네티스/도커] 3 - 쿠버네티스에서의 도커, 젠킨스, 프로메테우스, 그라파나 (0) | 2024.04.14 |
| [쿠버네티스/도커] 2 - 쿠버네티스란, 쿠버네티스 기본 사용법 (0) | 2024.02.25 |