![[Deep Learning] Optimizer](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FAH58V%2FbtqDyD7qEj4%2FAAAAAAAAAAAAAAAAAAAAAA7WukIte6v8gTeQ7eiWe4C1RorjkXfs1tIyeSFXa2cA%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Dhj%252F80VCvShvjwkNBHTmpbPaW%252BiA%253D)
[Deep Learning] Optimizer
Optimizer란 loss function을 통해 구한 차이를 사용해 기울기를 구하고 Network의 parameter(W, b)를 학습에 어떻게 반영할 것인지를 결정하는 방법이다.
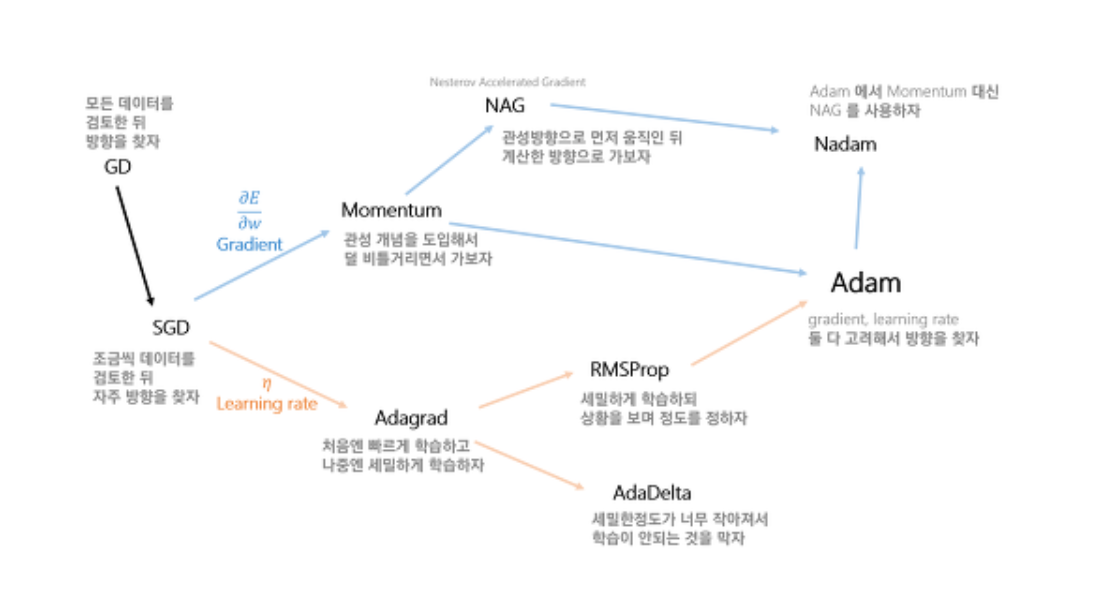
위의 많은 종료의 optimizer중에 몇가지만 자세히 알아보자.
Gradient Descent(GD)
1회의 학습 step시에, 현재 모델의 모든 data에 대해서 예측 값에 대한 loss 미분을 learning rate만큼 보정해서 반영하는 방법. gradient의 반대 방향으로 일정 크기만큼 이동해내는 것을 반복하여 Loss function의 값을 최소화하는 θ의 값을 찾는다.

optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
Arguments
- learning_rate : A tensor or a floating point value. The learning rate to use.
- use_locking: If True use locks for update operations.
- name: Optional name prefix for the operations created when applying gradients. Defaults to "GradientDescent".
Stochastic Gradient Descent(SGD)
한번 step을 내딛을 때 전체 데이터에 대한 loss function을 계산하면 매우 느리므로 이를 방지하기 위해 일부의 data sample이 전체 data set 의 gradient와 유사할 것이라는 가정하게 일부에 대해서만 loss function 계산

optimizer = tf.keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False).minimize(cost)
Arguments
- lr: float >= 0. Learning rate.
- momentum: float >= 0. Parameter that accelerates SGD in the relevant direction and dampens oscillations.
- decay: float >= 0. Learning rate decay over each update.
- nesterov: boolean. Whether to apply Nesterov momentum.
Momentum
이전 step의 방향(=관성)과 현재 상태의 gradient를 더해 현재 학습할 방향과 크기를 정함. Local minima를 빠져 나올 수 있다.(SGD의 Oscilation 현상 해결)

Adagrad(Adaptive Gradient)
Parameter 별로 gradient를 다르게 주는 방식. 많이 변화한 변수들은 G에 저장된 값이 커지기 때문에 step size가 작은 상태로, 적게 변화한 변수들은 상대적으로 step size가 큰 상태로 학습에 반영. 학습이 오래 진행되는 경우 G값이 너무 커져서 학습이 제대로 되지 않는다.

RMSProp
학습이 오래 진행되면 step size가 너무 작아지는 adagrad의 단점을 보완하기 위한 방법. 각 변수에 대한 gradient의 제곱을 계속 더하는 것이 아니라, 지수평균으로 바꾸어 G값이 무한정 커지지 않도록 방지하면서 변화량의 상대적인 크기 차이를 유지

Adaptive Moment Estimation(Adam)
Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장. RMSProp와 유사하게 지금까지 계산해온 기울기의 제곱값의 지수 평균을 저장. 학습 초반부에 m과 v가 0에 가깝게 bias되어 있을 것이라고 판단해 unbiased작업을 거친 후에 계산.

optimizer = tf.train.AdamOptimizer(
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
epsilon=1e-08,
use_locking=False,
name='Adam').minimize(cost)
Arguments
- learning_rate: A tensor or a floating point value. The learning rate.
- beta1: A float value or a constant float tensor. The exponential decay rate for the 1st moment estimates.
- beta2: A float value or a constant float tensor. The exponential decay rate for the 2nd moment estimates.
- epsilon: A small constant for numerical stability. This epsilon is "epsilon hat" in the Kingma and Ba papaer.
- use_locking: If True use locks for update operations.
- name: Optional name for the operations created when applying gradients. Defaults to "Adam".
Example
MNIST classifier에 dropout과 adam optimizer적용하기
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
keep_prob = tf.placeholder(tf.float32)
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
W1 = tf.Variable(tf.random_uniform([784, 256], -1., 1.))
b1 = tf.Variable(tf.random_uniform([256], -1., 1.))
L1 = tf.sigmoid(tf.matmul(X, W1) + b1)
L1 = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.random_uniform([256, 256], -1., 1.))
b2 = tf.Variable(tf.random_uniform([256], -1., 1.))
L2 = tf.sigmoid(tf.matmul(L1, W2) + b2)
L2 = tf.nn.dropout(L2, keep_prob)
W3 = tf.Variable(tf.random_uniform([256, 128], -1., 1.))
b3 = tf.Variable(tf.random_uniform([128], -1., 1.))
L3 = tf.sigmoid(tf.matmul(L2, W3) + b3)
L3 = tf.nn.dropout(L3, keep_prob)
W4 = tf.Variable(tf.random_uniform([128, 10], -1., 1.))
b4 = tf.Variable(tf.random_uniform([10], -1., 1.))
logits = tf.matmul(L3, W4) + b4
hypothesis = tf.nn.softmax(logits)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=logits))
opt = tf.train.AdamOptimizer(
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
epsilon=1e-08,
use_locking=False,
name='Adam').minimize(cost)
batch_size = 100
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# epoch을 15번. batch size가 100인데 총 데이터수가 55,000. 따라서 1epoch는 55,000 / 100 = 550 번. 여기선 550 X 15번 돈다는 의미
for epoch in range(15):
avg_cost = 0
# 한번 돌때 몇번의 batch가지는지
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
# training data를 batch size만큼 불러옴. 각각 image data, label data
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# cost만 가져옴. opti는 무시
c, _ = sess.run([cost, opt], feed_dict={X:batch_xs, Y:batch_ys, keep_prob:0.75})
# 한 epoch당 나오는 cost의 average
avg_cost += c / total_batch
print('Epoch:', '%d' % (epoch+1), 'cost =', '{:.9f}'.format(avg_cost))
is_correct = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print("Accuracy", sess.run(accuracy, feed_dict={X:mnist.test.images, Y:mnist.test.labels, keep_prob:1}))'CS > Deep Learning' 카테고리의 다른 글
| [Deep Learning] 가중치 초기화 & Check Point (0) | 2020.05.11 |
|---|---|
| [Deep Learning] Auto-Encoder (1) | 2020.04.24 |
| [Deep Learning] Dropout (0) | 2020.04.19 |
| [Deep Learning] Regularization (0) | 2020.04.19 |
| [Deep Learning] 손실 함수(Cost function) (0) | 2020.04.05 |