![[Deep Learning] 합성곱 신경망 (Convolution Neural Network, CNN)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FE296E%2FbtqD3cP3UqE%2FAAAAAAAAAAAAAAAAAAAAAAuN0XdbRBE_dj4pNgChgIDBvzYd7MJAQklraOXD2Ie6%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DJWHCfuEcsw%252FN0ssQXkuQsUEqi3k%253D)
[Deep Learning] 합성곱 신경망 (Convolution Neural Network, CNN)
합성곱 신경망 (Convolution Neural Network, CNN)
기존의 방식인 Fully-connected Neural Network의 입력은 항상 1차원 배열이다. 또한 모든 값들이 완전 연결되어 있으므로 전체 픽셀의 모든 관계를 다 계산 해야한다. 이렇게 이미지의 3차원 배열 형상(x, y, RGB)을 무시하고 1차원 배열로 flatten해서 학습하면 여러문제가 생긴다. 이미지의 전체적인 관계를 고려하지 못해서 변형된 데이터에 매우 취약하다는 것(Topology)과, 이미지의 특정 픽셀은 주변 픽셀과 관련이 있다는 특성을 잃어버린다는 것(Locality)(이 경우 이미지를 조금만 변형해도 아예 다른 Object 로 인식한다는 문제가 있다), 그리고 모든 이미지마다 학습해야 해서 망의 크기, 변수의 개수, 학습 시간이 매우 커진다는 것이다. 이것은 매우 비효율적으로 계산하는 결과를 초래한다.
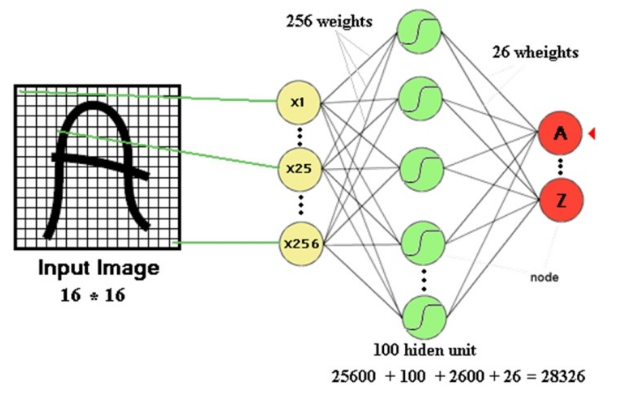
위의 문제에 대해 해결방안으로 나온 CNN은 이미지의 공간 정보를 유지한 상태로 학습이 가능하다.
CNN은 행렬로 표현된 필터의 각 요소가 데이터 처리에 적합하도록 자동으로 학습되게 하는 모델이다. 즉 CNN 모델은 이미지 분류 정확도를 최대화하는 필터를 자동으로 학습한다. CNN은 크게 3가지로 구성된다.
- Convolution layer
- Sub-sampling(pooling) layer
- FC layer(Affine)
아래 사진은 Convolution layer와 Sub-sampling(pooling) layer를 이미지의 특징을 추출(feature extration)하는 부분으로, FC(fully connected) layer를 클래스를 분류하는(Classification) 부분으로 나눠놨다. Convolution layer는 입력 데이터에 필터를 적용한 후 활성화 함수를 반영하는 필수 요소이다. Pooling layer는 선택적 레이어다. Feature extraction부분과 classification 부분 사이에는 이미지 형태의 데이터를 배열 형태로 만드는 Flatten layer가 위치한다.
CNN은 이미지 특징 추출을 위하여 입력데이터를 필터를 이용해 합성곱을 계산하고, 그 결과를 이용해 Feature map을 만든다. Convolution layer는 필터의 크기, stride, padding 적용 여부, max pooling 크기에 따라서 출력 데이터의 shape이 변경된다.

그럼 CNN에서 나오는 용어들을 살펴보자.
합성곱 (Convolution)
합성곱은 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자이다. 계산 과정은 아래 그림과 같다.

채널 (Channel)
채널의 예시를 들어보자. 컬러 이미지는 3차원 데이터로 3개의 채널로 구성된다(RGB). 반면에 흑백 사진은 2차원 데이터로 1개의 채널로 구성된다. Convolution layer에 유입되는 입력 데이터에는 한 개 이상의 필터가 적용된다. 1개 필터는 feature map의 채널이 된다. 즉, convolution layer에 n개의 필터가 적용되면 출력 데이터는 n개의 채널을 갖게 된다.
필터링 (Filtering) & 필터 (Filter)
필터링은 이미지 처리 분야에서 광범위하게 이용되고 있는 기법으로써, 이미지에서 테두리 부분을 추출하거나 이미지를 흐릿하게 만드는 등의 기능을 수행하기 위해 이용된다. 필터의 예시는 아래 표와 같다. 행렬로 표현된 이미지에 원하는 필터를 합성곱(convolution) 하면 결과로 오른쪽 사진이 나온다.

위와 같이 필터링을 하기 위해, 즉 이미지의 특징을 찾아내기 위한 공용 파라미터를 필터(Filter)라고 한다. 필터는 커널(kernel)이라고도 불린다. CNN에서 학습의 대상은 필터다. 필터는 지정된 간격(Stride, 뒤에서 설명)으로 이동하면서 전체 입력데이터와 합성곱하여 feature map(=추출된 특성)을 만든다. 이렇게 채널별로 feature map이 만들어지면 각각을 합산하여 최종 feature map으로 반환한다. 입력 데이터는 채널 수와 상관없이 필터 별로 1개의 feature map이 만들어진다. Feature map에 활성 함수(Activation function)를 적용하면 Activation map이 나온다. 즉, convolution layer의 최종 출력 경과가 activation map이다.
Stride
Stride란 필터를 적용하는 위치의 간격을 의미한다. 즉, 위의 합성곱을 하는 이미지에서 계산을 할때마다 몇 칸씩 이동할지 정해주는 것이 Stride다.
# strides의 두, 세번째 값인 1, 1 = 가로 세로 1칸을 의미
conv2d = tf.nn.conv2d(image, weight, strides=[1, 1, 1, 1], padding='VALID')
패딩 (Padding)
Convolution layer에서 feature map의 크기는 입력데이터보다 작다. 따라서 줄어든 부분을 채워줘야 하는데 이렇게 Convolution으로 인한 image 모서리 부분 정보 손실 방지를 위해 입력데이터 주변을 특정값으로 채우는 것을 패딩(Padding)이라고 한다. 일반적으로 그 값을 0으로 채워 넣는 zero padding을 많이 사용한다. 이는 NN이 이미지의 외각을 인식하는 학습 효과도 있다.
# valid, same 등의 값이 들어갈 수 있음
conv2d = tf.nn.conv2d(image, weight, strides=[1, 1, 1, 1], padding='VALID')
풀링 (Pooling)
풀링 (Pooling)은 가로 세로 방향의 공간을 줄이는 연산을 의미한다. 따라서 pooling layer는 convolution layer의 출력 데이터(Activation map)을 입력으로 받아서 크기를 줄이거나 특정 데이터를 강조하게 된다. 이는 출력의 해상도를 낮춰 변형이나 이동에 대한 민감도를 감소시키는 효과가 있고 이미지를 줄이기 때문에 학습할 노드의 수가 줄어들어 학습속도를 높이는 효과가 있다. 하지만 정보 손실이 발생하기도 한다. 종류에는 Max Pooling, Average Pooling, Min pooling이 있다. 이중 Max Pooling을 일반적으로 사용한다.
# Max Pooling
pool = tf.nn.max_pool(image, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
pooling layer는 convolution layer와 비교해서 다음과 같은 특징이 있다.
- 학습대상 파라미터가 없다.
- pooling layer를 통과하면 행렬의 크기가 감소한다.
- pooling layer를 통해서 채널 수의 변경은 없다.
Fully Connected Layer
이전 게층의 모든 뉴런과 결합된 형태의 레이어를 의미한다.
Implementing CNN
위를 바탕으로, 이제 CNN을 tensorflow를 이용해 구현해보자. 데이터는 MNIST를 이용한다. 구현할 모델은 아래 그림과 같다.
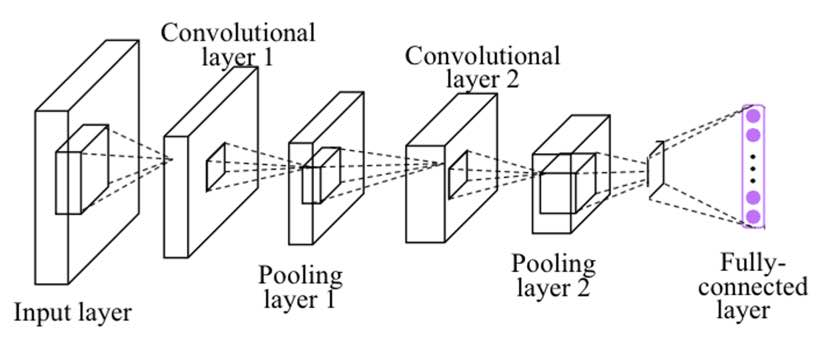
1. Convolution layer (first) + Pooling layer (first)
mnist = input_data.read_data_sets("./mnist/data/", one_hot=True)
learning_rate = 0.001
training_epochs = 15
batch_size = 100
# X = image data
X = tf.placeholder(tf.float32, [None, 784])
# -1 = number of image, '-1' means none/don't know
# 1 = channel, 1 bcz no color
X_img = tf.reshape(X, [-1, 28, 28, 1])
Y = tf.placeholder(tf.float32, [None, 10])
# 3, 3 means filter size
# 1 means channel of input image
# 32 means number of filter
W1 = tf.get_variable(name="W1", shape=[3, 3, 1, 32], initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(name="b1", shape=[32], initializer=tf.contrib.layers.xavier_initializer())
# same means output image size = input image size
C1 = tf.nn.conv2d(X_img, W1, strides=[1, 1, 1, 1], padding='SAME')
L1 = tf.nn.relu(tf.nn.bias_add(C1, b1))
# 2, 2 in ksize means kernel size
L1_pool = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
2. Convolution layer (second) + Pooling layer (second)
# 32 = previous filter number
W2 = tf.get_variable(name='W2', shape=[3, 3, 32, 64], initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable(name='b2', shape=[64], initializer=tf.contrib.layers.xavier_initializer())
C2 = tf.nn.conv2d(L1_pool, W2, strides=[1, 1, 1, 1], padding='SAME')
L2 = tf.nn.relu(tf.nn.bias_add(C2, b2))
L2_pool = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
L2_flat = tf.reshape(L2_pool, [-1, 64*7*7])
3. Fully-Connected Layer
W3 = tf.get_variable(name='W3', shape=[64*7*7, 10], initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(name='b3', shape=[10], initializer=tf.contrib.layers.xavier_initializer())
logits = tf.nn.bias_add(tf.matmul(L2_flat, W3), b3)
hypothesis = tf.nn.softmax(logits)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
+ Hyper Parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 100
참고
'CS > Deep Learning' 카테고리의 다른 글
| [Deep Learning] Attention 메커니즘 (0) | 2020.06.03 |
|---|---|
| [Deep Learning] Recurrent Neural Network(RNN) (0) | 2020.05.20 |
| [Deep Learning] 가중치 초기화 & Check Point (0) | 2020.05.11 |
| [Deep Learning] Auto-Encoder (1) | 2020.04.24 |
| [Deep Learning] Optimizer (1) | 2020.04.19 |